

That question may sound simple, but it is one of the most pressing problems on the minds of companies building with language models today. Evaluating generative AI models has proven challenging, and it boils down to two sticking points:
In this post, we’ll explore how people are trying to solve each of these problems and what shortcomings still exist that are causing headaches for developers.
Part of the problem with evaluating language models: they’re used for a wide variety of tasks!
The same models are being used to:
To that end, it’s worth cataloging some of the dimensions upon which you might measure how “good” a language model is:
There are also some more standard API assessments you probably care about:
All of this is to say: no single metric will ever describe the overall “goodness” of a model. Most of the discourse around which model is the best today (the consensus in most circles is that GPT-4 is the “best” model available today) is debating on some complex blend of the above factors.
The most common way to measure models today is to score those models on benchmarks built to evaluate generated text across several tasks, the most popular being the HELM benchmark. HELM is composed of a collection of “scenarios” that measure the capabilities of LLMs on a range of tasks like “question answering,” “knowledge base completion,” and “story writing.”
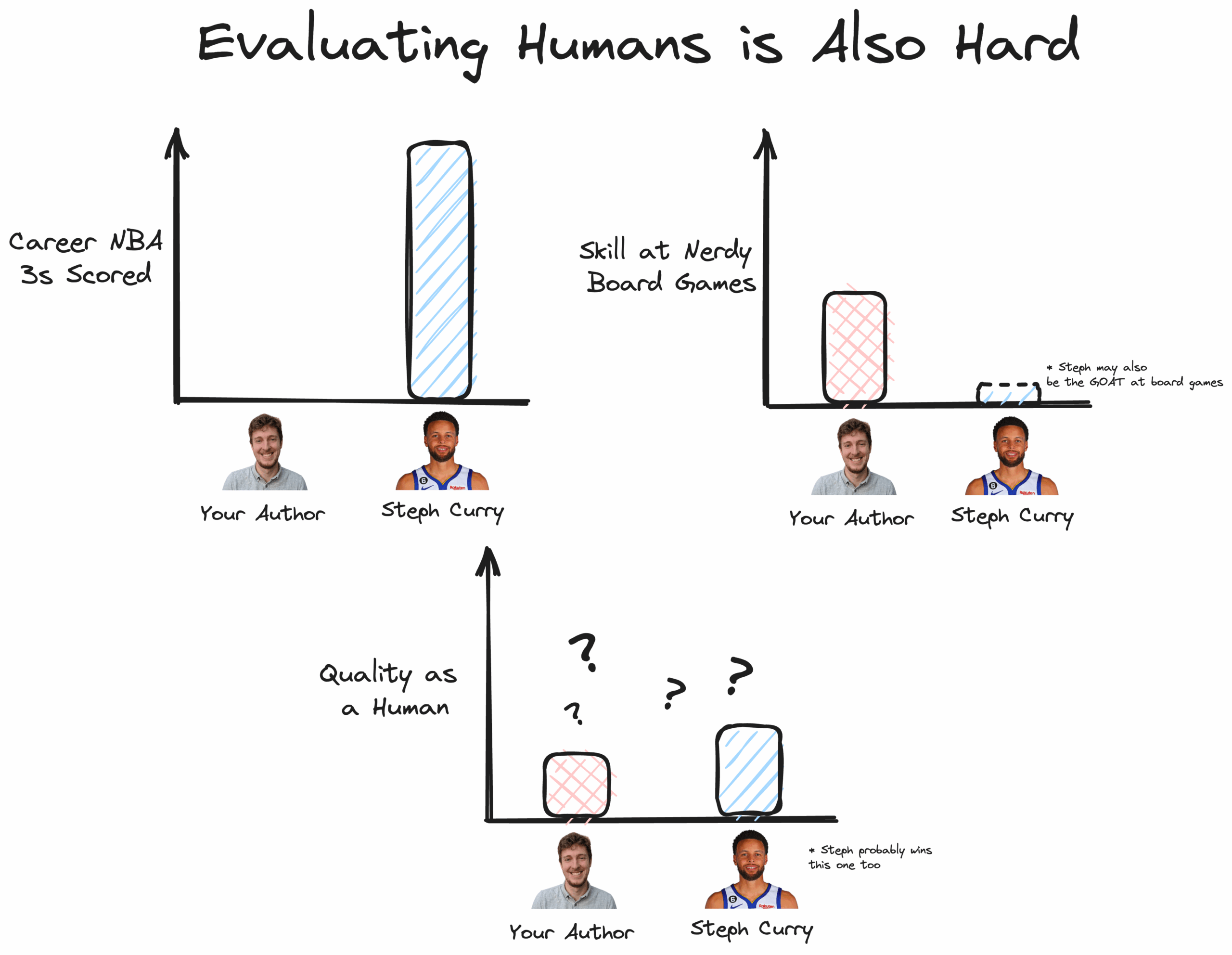
These benchmarks are similar to standardized tests like the ACT or SAT – measuring capabilities across several subjects. One notable fact about standardized tests: they’re not used as a sole measure of the “quality” of a college applicant. They are primarily a tool used to understand one person’s capabilities. Who knows how good an individual student could be in the right environment? Who knows how capable a new model could be with the right prompt?
To that end – there are several emerging methods that teams are using to evaluate the quality of models, including a lot of head-to-head measurements of user preference. My favorite of these evaluations is the Chatbot Arena by the LMSYS Org out of UC Berkeley, which pits models head-to-head with crowdsourced preferences, then assigns models an Elo rating:

Of course, this also has notable shortcomings – what users want from a generic internet chatbot may be utterly unrelated to what you want from the LLM you use to build your product. These chatbots might be really “nice,” but if you’re making an evil assistant, they might be terrible.
This leaves us with probably the most common way teams evaluate LLMs today: unscalable, untested, “vibes-based” human preference. Most teams we’ve talked to have a spreadsheet where they test models against several different inputs, and before shipping a model to production, they do an “eye test” to validate that the outputs look good. When choosing which model to use, nearly everyone blindly chooses GPT-3.5 or GPT-4 — there is a consensus (again, primarily vibes) that they are the best models for most tasks today. If benchmarks are similar to a standardized test, these evaluations are more like short job interviews.
The primary way to scale this bespoke human preference evaluation is with a lot of people. To that end, some companies are hiring (or contracting) scaled workforces to test LLM extensively against their internal metrics. Scale AI is offering this testing as a service, so companies can quickly spin up teams of evaluators. We don’t expect this to be a tenable long-term solution for teams building LLM-powered features.
Finally, one common approach is to collect user feedback: ship a model to production and wait to see how your users like it. While this approach has its merits (there is no more accurate way to measure what your users like than to ask them directly), it also has obvious shortcomings:
(1) you need a lot of users in the first place to get good data
(2) it can be problematic to ship a model that you’re not confident in, particularly if you’re working in regulated industries.
We think there is likely a better long-term solution.
So how do we scale our ability to evaluate and understand how well a model will perform at a given task? A few emerging approaches hold some promise.
Scaling testing with models: The most promising direction to help solve model testing challenges is to use machine learning systems to automate and scale developers’ ability to evaluate models.
In our mind, the most fundamental component of this approach is the reward model, which has become prominent for its critical role in Reinforcement Learning from Human Feedback (RLHF). Reward models are machine learning systems built to model user preference — essentially, a model that can look at generated text and predict how a user will respond. Fundamentally, nearly every product has different users, meaning reward models are not one-size-fits-all. Models built to be helpful chat assistants may be relatively poor copywriters; they might opt to try to help the user rather than write copy.
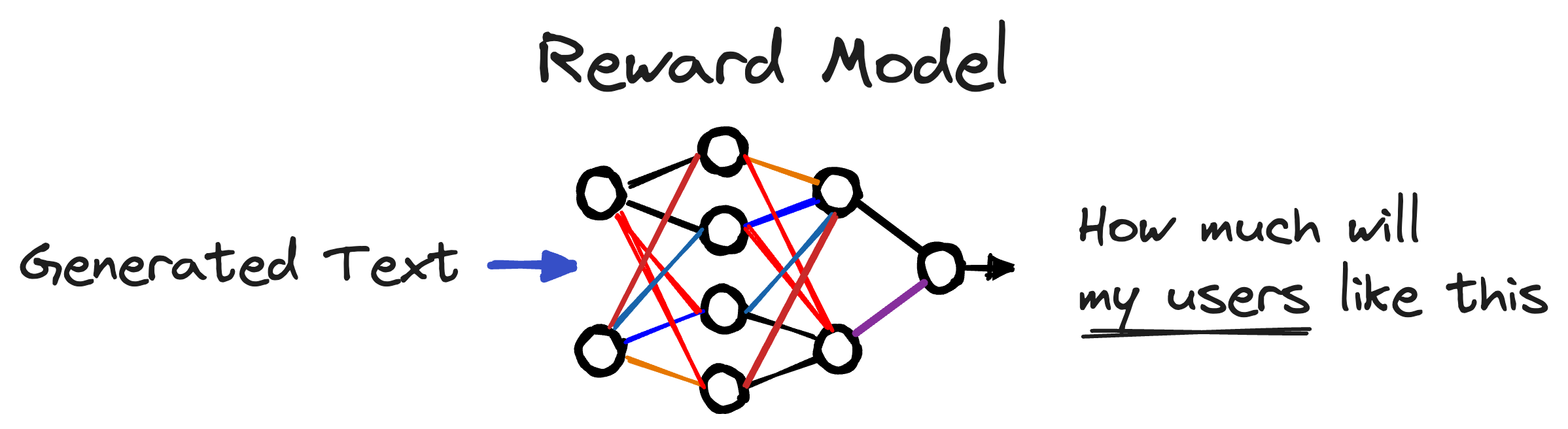
We expect an explosion in the prominence and use of reward models, and there is a considerable opportunity for developer tools that enable and simplify the construction and use of these models.
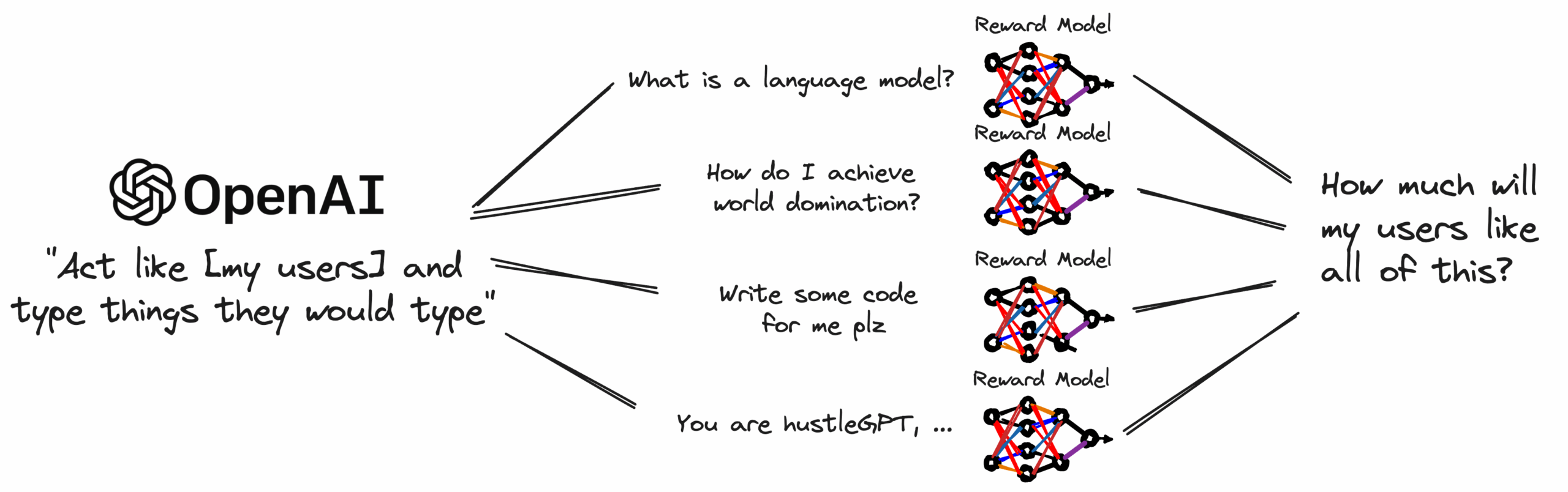
Simulating user sessions: even with a great reward model, developing extensive test cases for open-ended product interfaces (like chatbots) can be challenging. Users are complicated, and there are many of them — it’s hard to imagine every possibility!
We also expect machine learning to play a critical role in simulating user sessions. With the recent explosion of LLM-based agents like BabyAGI and AutoGPT, there is an opportunity for LLM agents to create user sessions that scale our ability to build test cases and evaluate the performance of LLMs across a broader range of potential user intents.
We believe the future of LLMs will see two key innovations:
With this foundation, developers can build robust systems that evaluate the quality of language models before they are put into production. These systems will make currently painful tasks easier: choosing which model to use, writing good prompts, and complying with current or future regulations. This tooling will be a critical piece of the future toolchain that developers will use to build intelligent software features.
If you’re working on developer tools that will unlock the potential of LLMs for the 30 million developers in the world, let us know. We’d love to help out.
For weekly updates on the fast-paced world of AI, subscribe to David Hershey’s column, Generally Intelligent, on Substack.